Learning Objectives: Continuous Deilivery & DevOps
- - Understand the challenges and benefits of Continuous Software Delivery
- - Able to apply simple automation tools to get started with continuous integration
- - Grasp the idea of DevOps and how it can benefit organisations
Join the interactive presentation during the lecture!

https://tudelft.on.worldcat.org/oclc/606556181
Hollistic perspective

https://tudelft.on.worldcat.org/oclc/1369407431
Applied perspective
The challenge of Software Delivery

How good is that change?
When should it be installed?
The challenge of Software Delivery
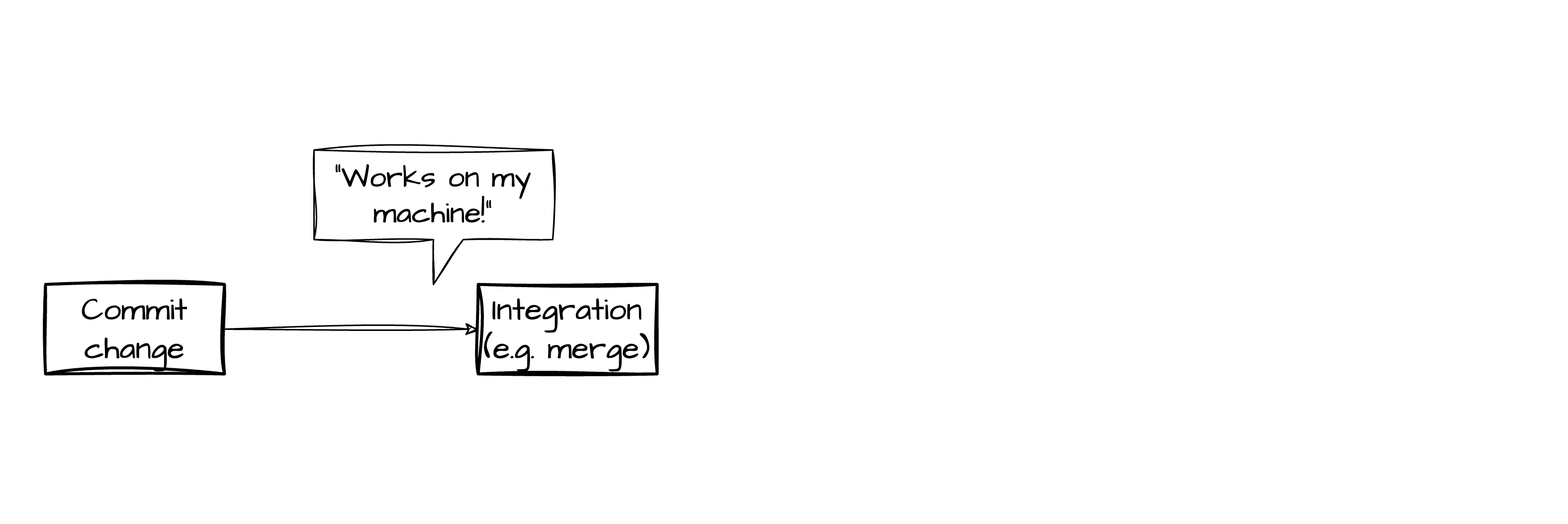
How good is that change?
The challenge of Software Delivery
How good is that change?
The challenge of Software Delivery
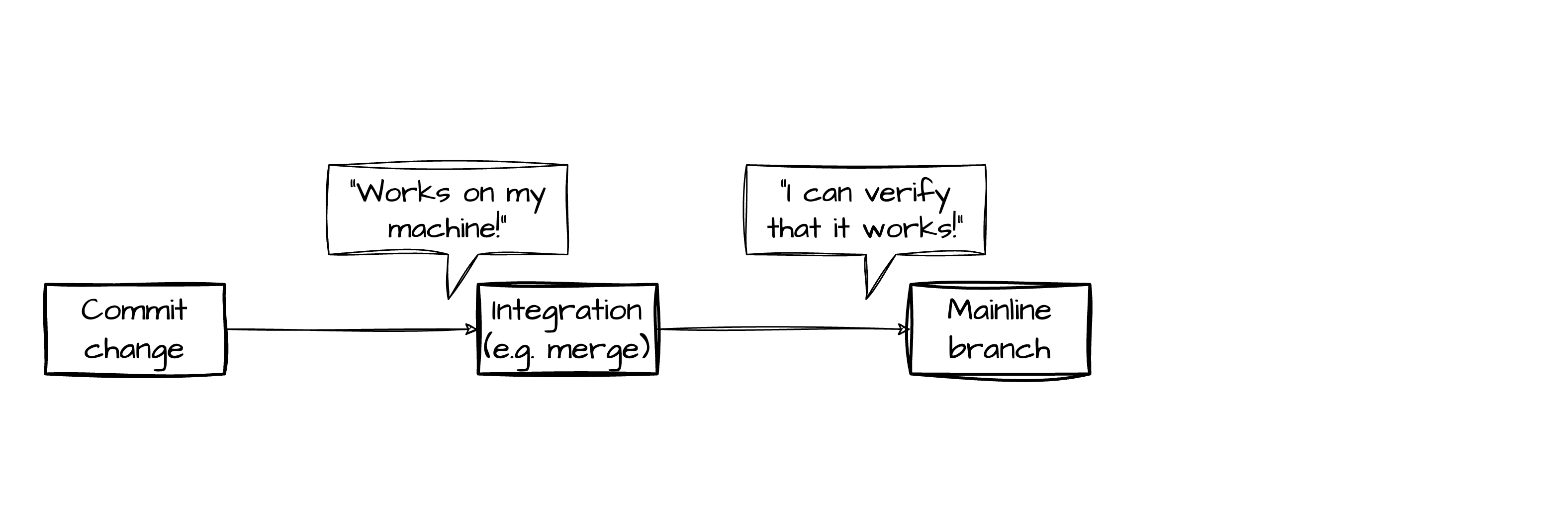
When should it be installed?
The challenge of Software Delivery
When should it be installed (and by whom)?
The challenge of Software Delivery
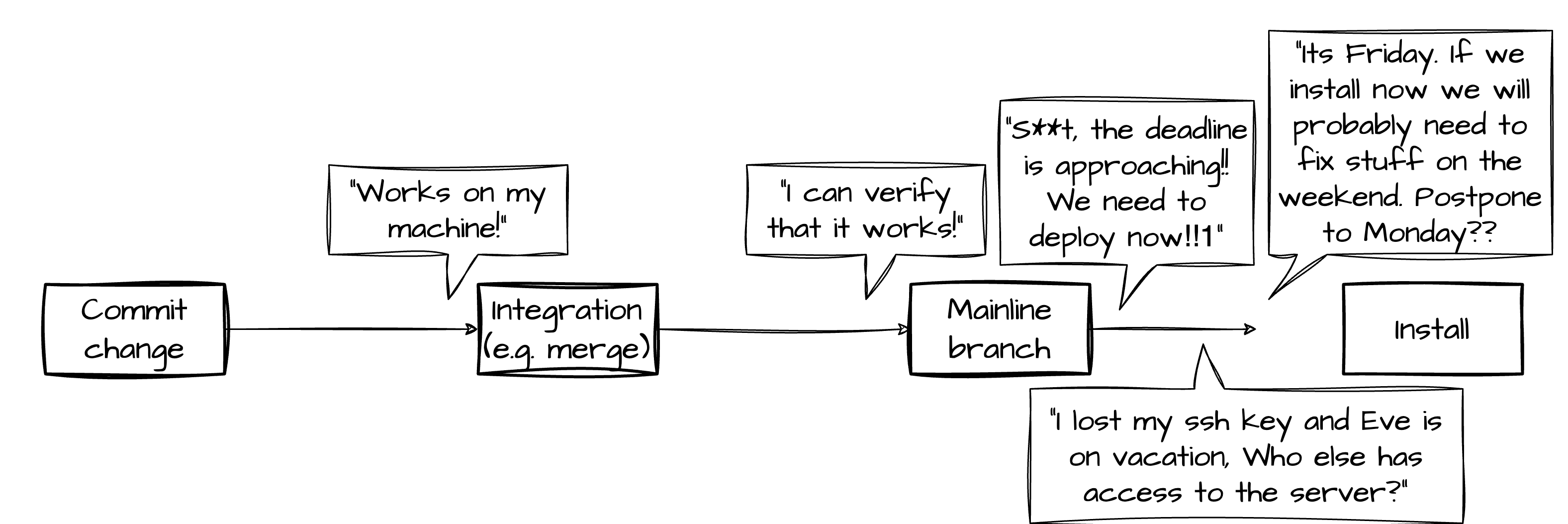
When should it be installed (and by whom, and who is responsible for consequences)?
Example: Voyager 1

Hardware age: > 50 years
Cost: >1.000.000.000$
Distance: 22.000.000.000 km
Roundtrip time: ~44h
Bandwidth: ~100 bits/s
Let's do a software update!
What are the challenges?
Voyager1: Challenges for Updates
- Technology with limited capabilities
- Fast correction of errors not possible
- Very limited reachability
Example: Voyager 1
No backup system
No on-premise maintainance
Very high risk
Works on my machine
Integration and Delivery
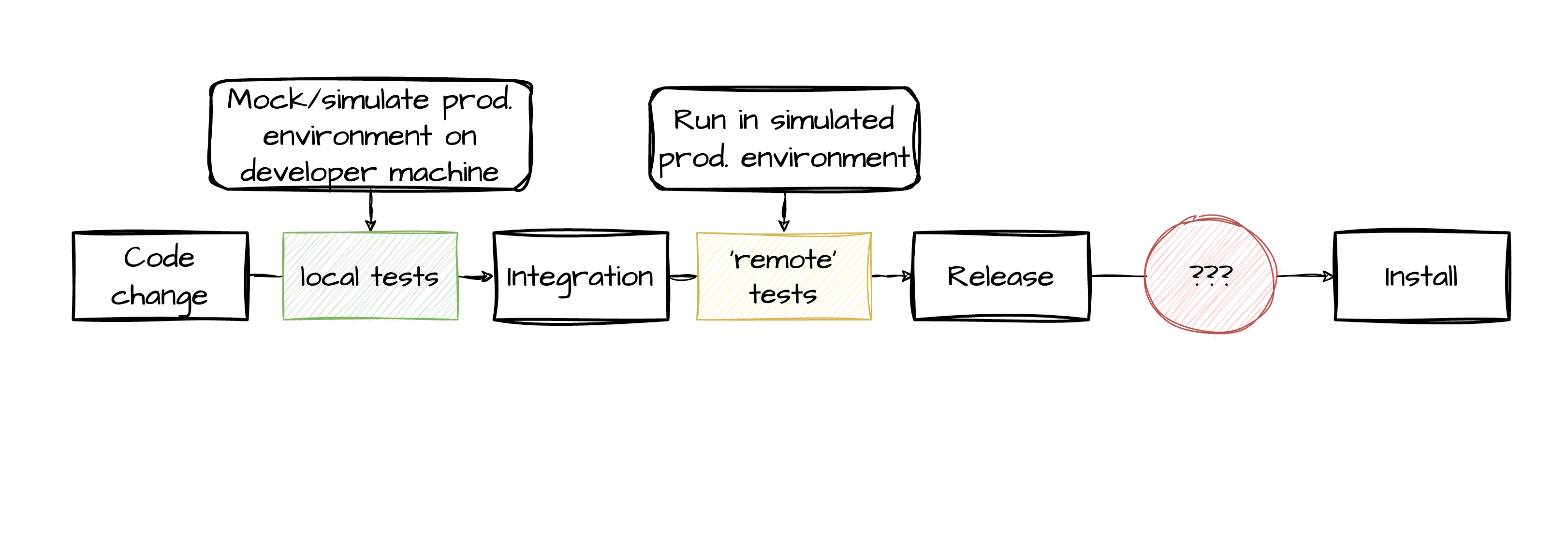
How good is that change? Prove that its good!
Integration and Delivery
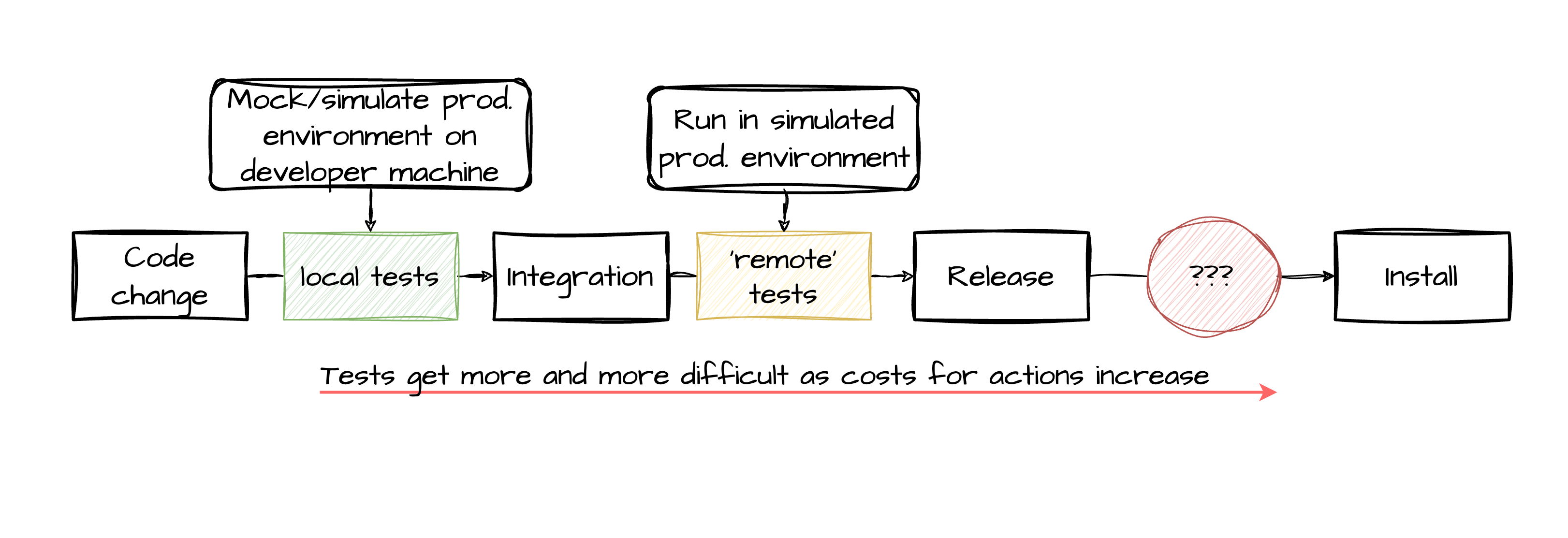
How good is that change? Prove that its good!
Integration and Delivery
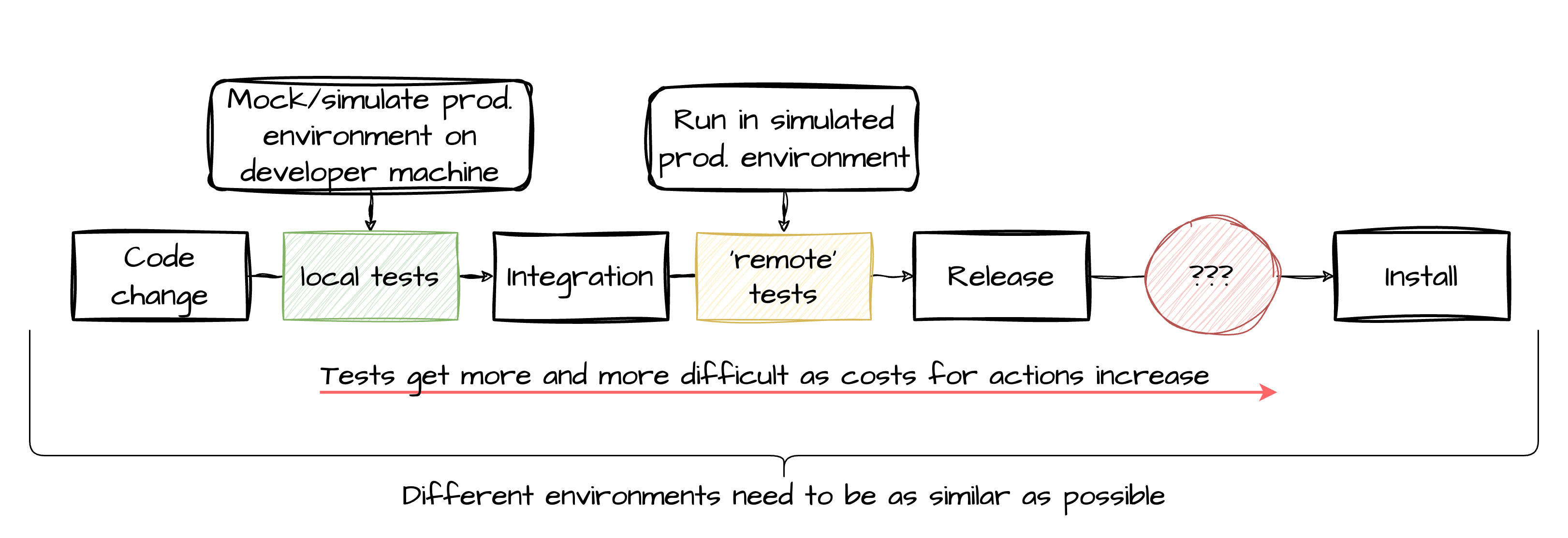
How good is that change? Prove that its good!
Integration and Delivery
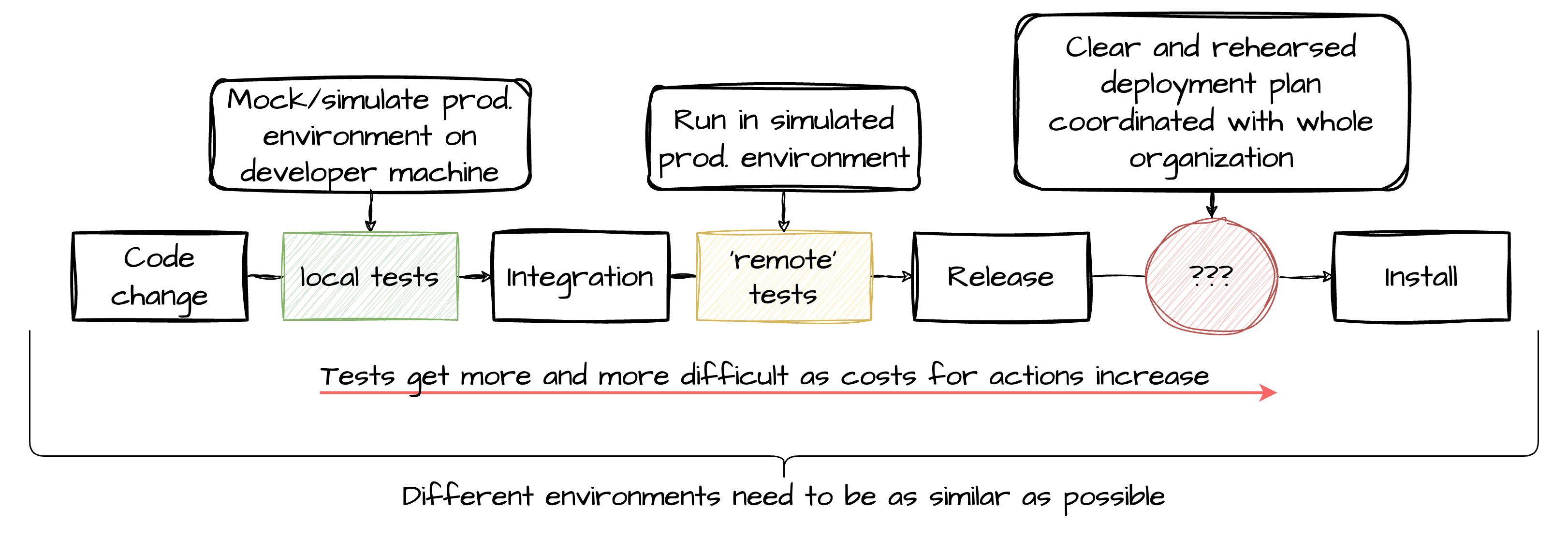
When should it be installed (etc.)? Organisational, not technical decision
Integration and Delivery
Means of software delivery have a huge impact

Comparison: Firefox (nightly)
Which needs does nightly delivery of firefox fullfill?
What is the organisational context at mozilla?
Comparison: Firefox (nightly) - context
What is the organisational context at mozilla?Advocating free software values and practices
SW used by community
Contributions from 'outside' encouraged
Comparison: Firefox (nightly) - needs
Which needs does nightly delivery fullfill?
e.g. transparency, feedback, feeling of progress for contribuors
Deployment/Delivery as an architectural view
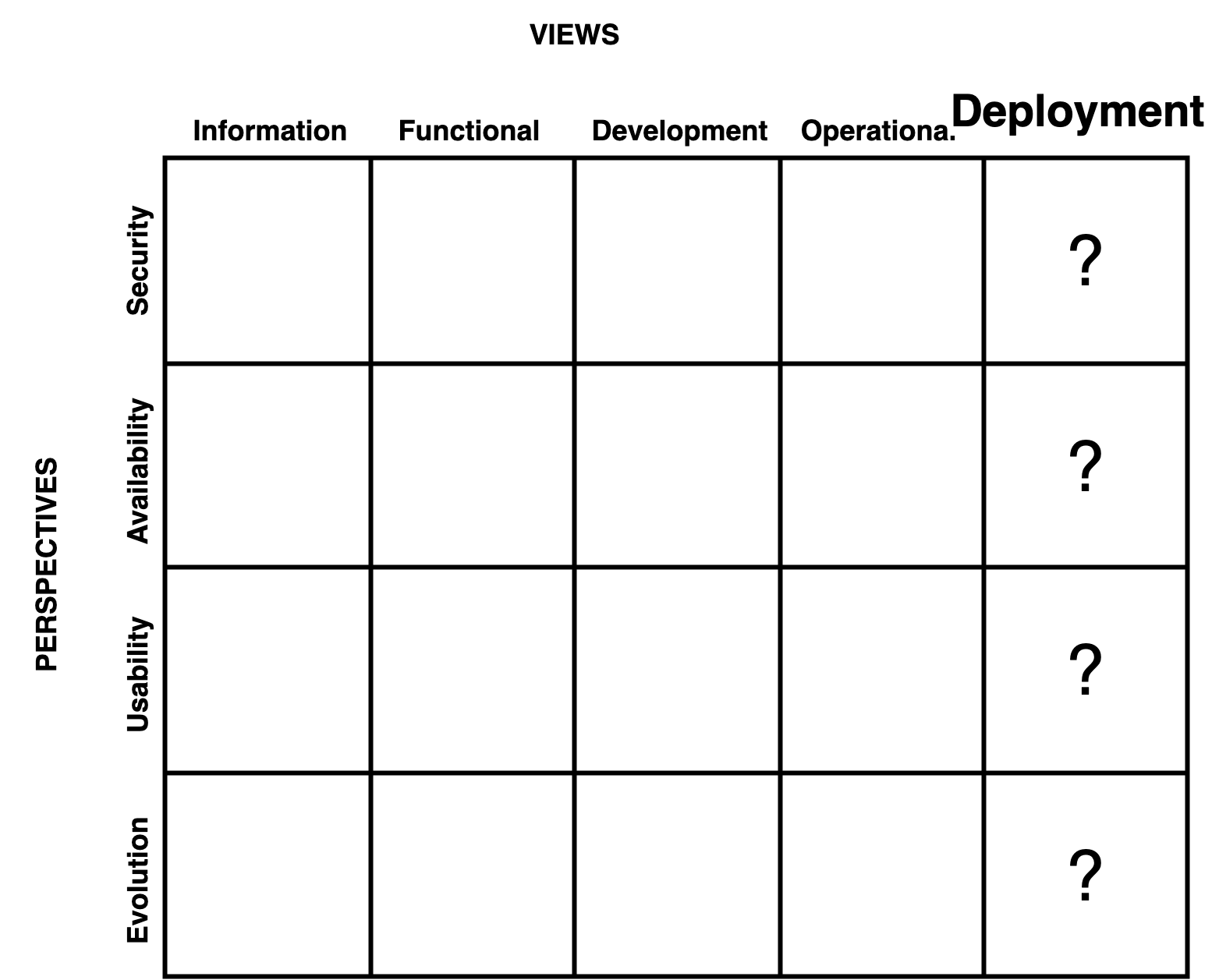
SW delivery should be considered in architecture planning
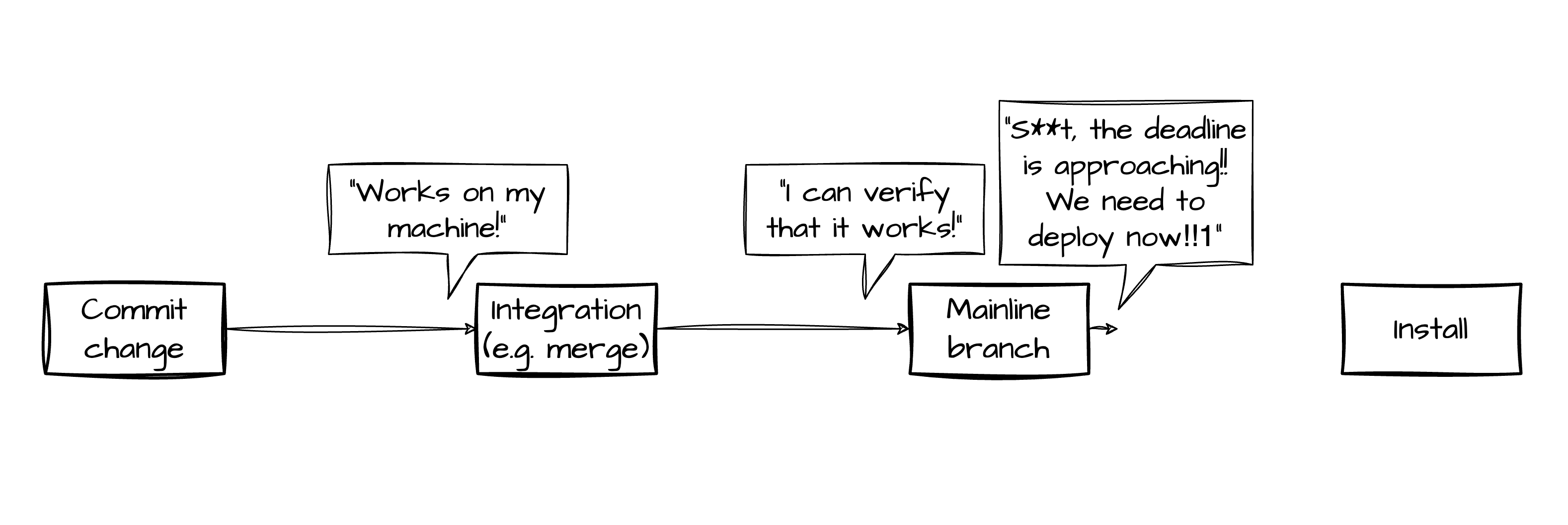
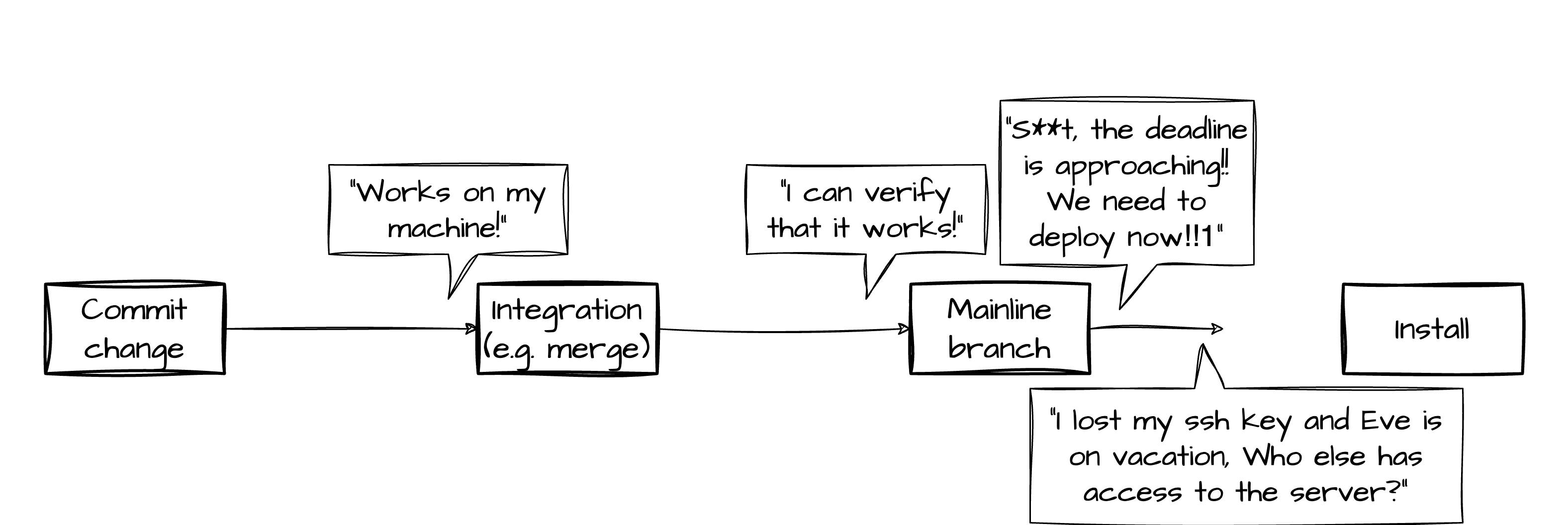
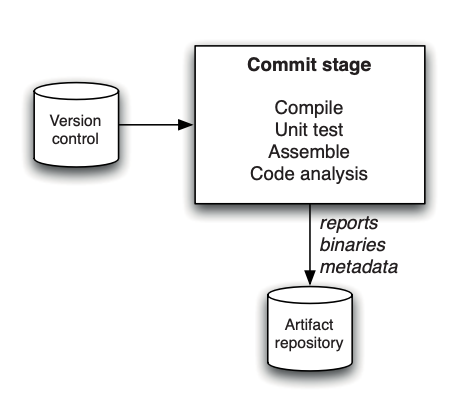
Integration, Delivery and Deployment Pipeline

Integration, Delivery and Deployment Pipeline
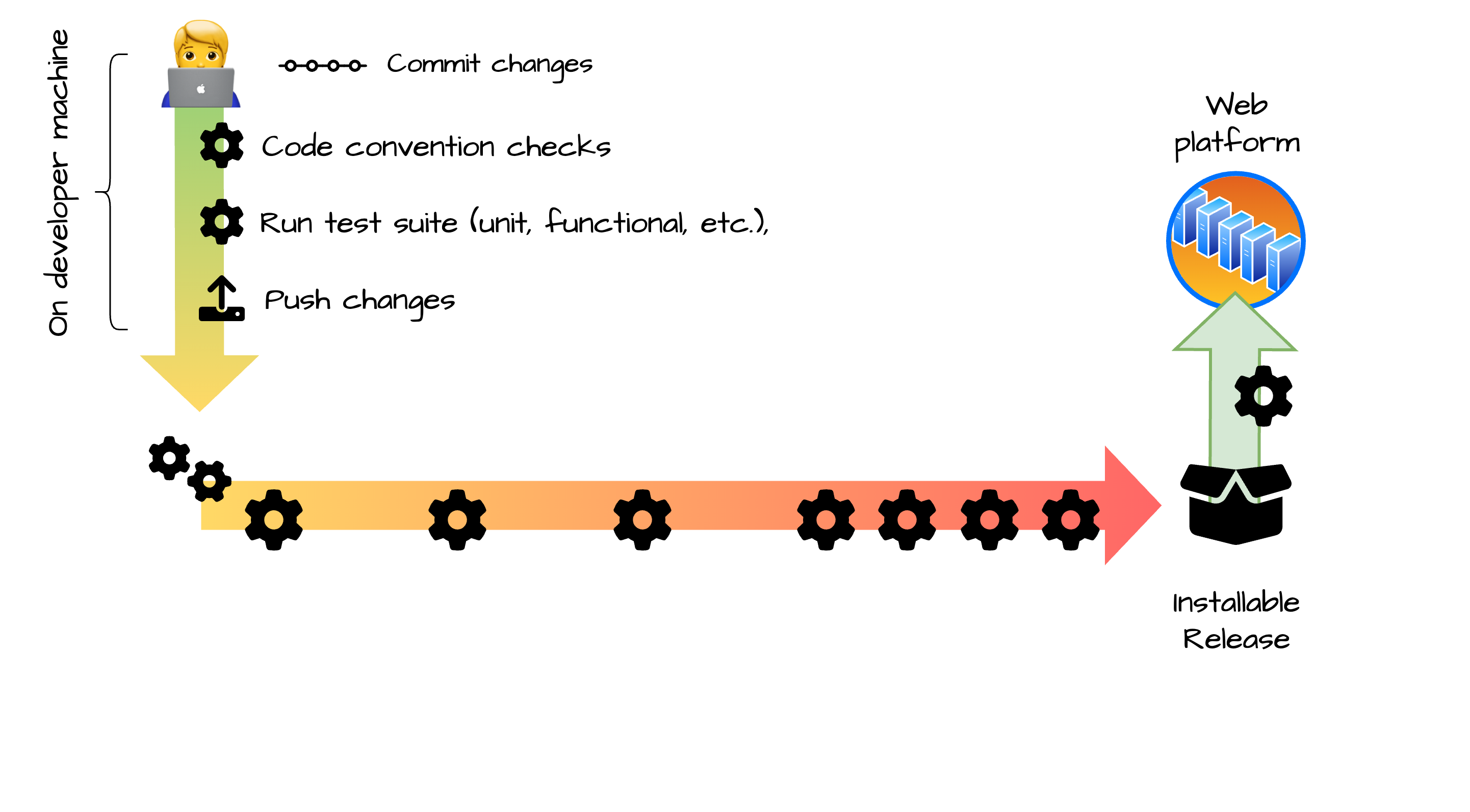
Integration, Delivery and Deployment Pipeline
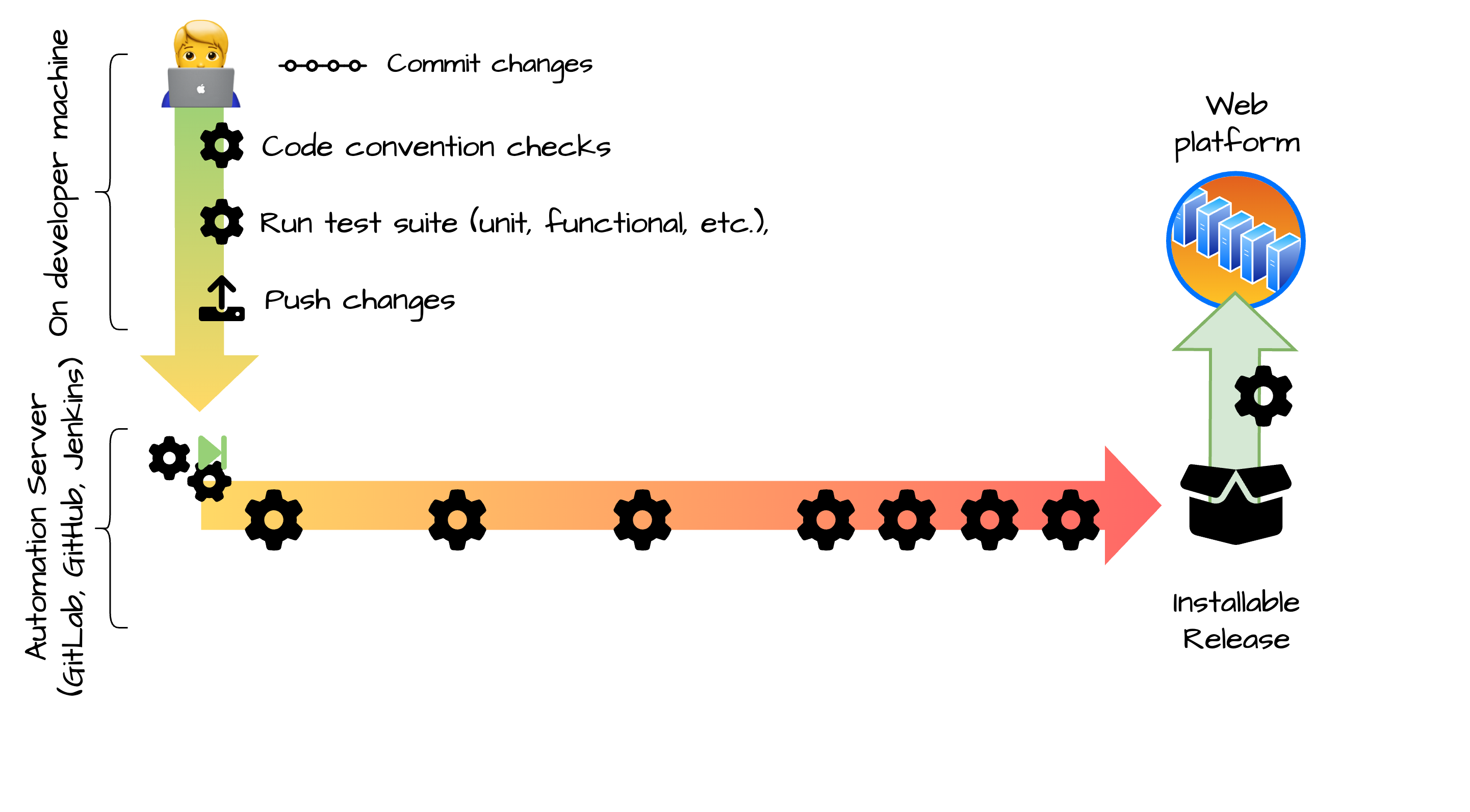
Integration, Delivery and Deployment Pipeline
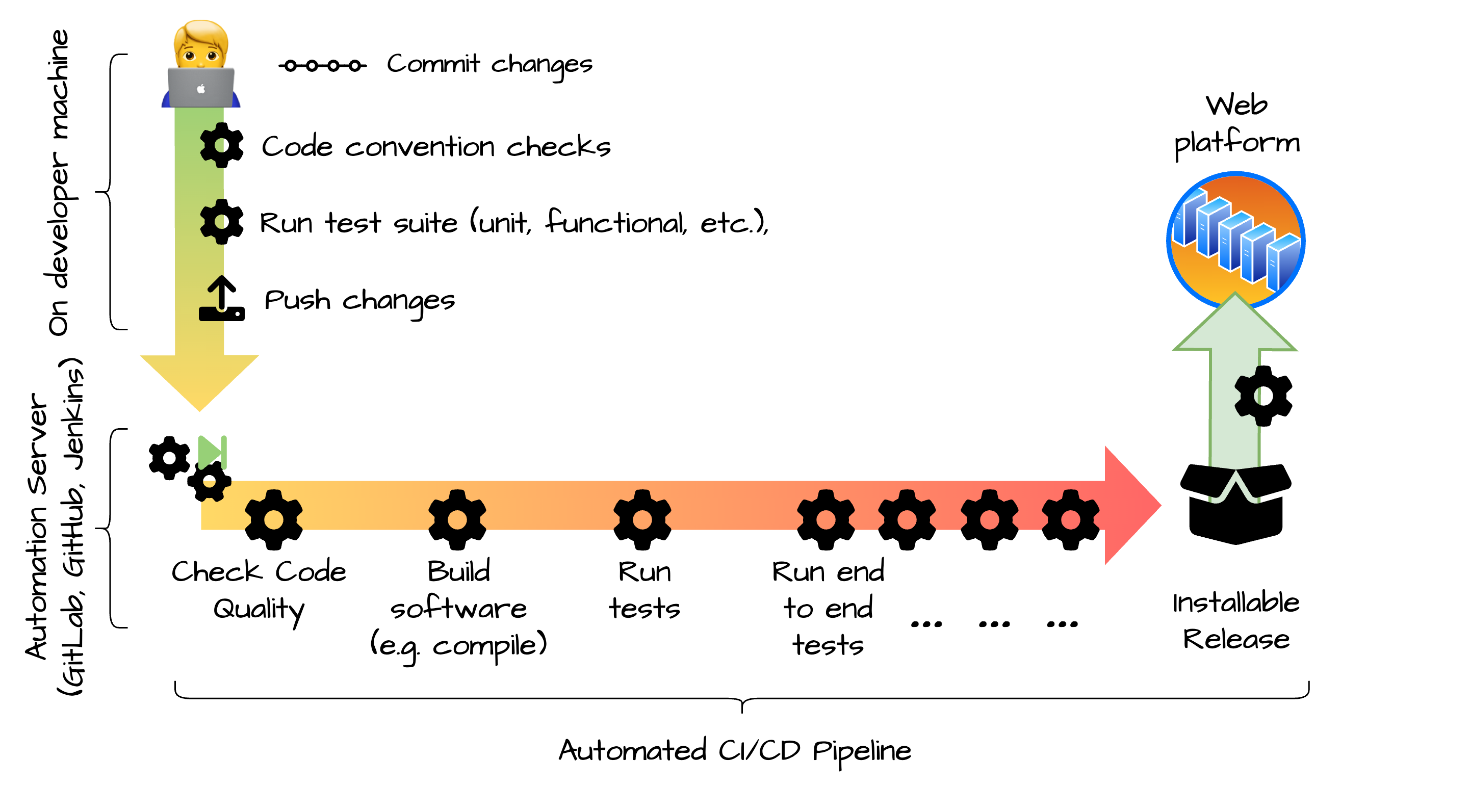
Integration, Delivery and Deployment Pipeline
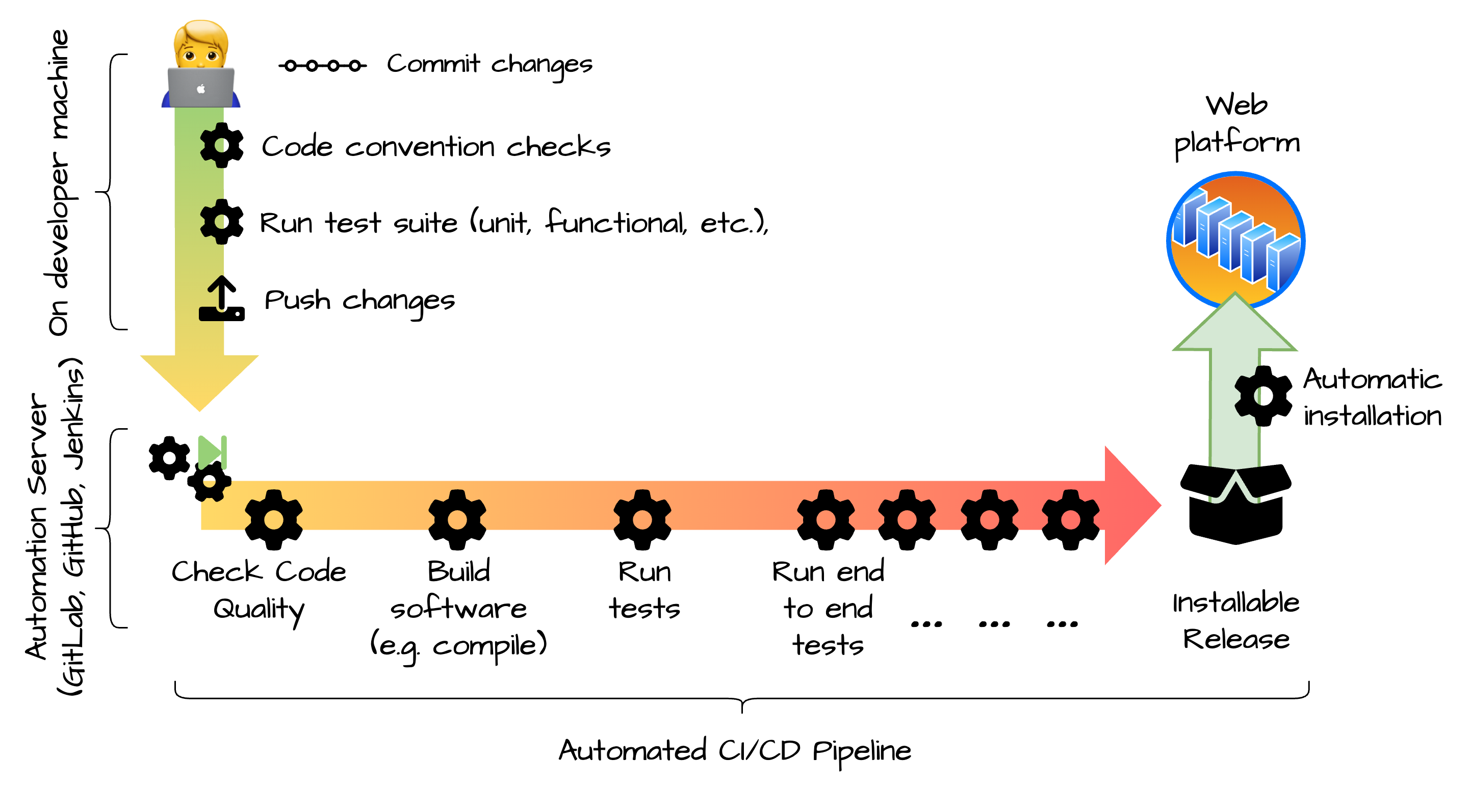
Continuous Delivery & Continuous Deployment
Can deploy mainline to production at any given moment
We may choose not to
→ business decision, not technical reason
Do deploy mainline to production with every change
Continuous Delivery (CD)
Idea: Every commit is constantly delivered rapidly
Means: Automate almost everything!
Goal: Gain confidence & reduce risk.
Value: Get rapid feedback & provide transparency.
Continuous Integrateion (CI)
Required before we can get to CD
Idea: Every commit integrated rapidly into mainline
Means: Automated test, build & config management
Goal: Accelarate development process (incl. review)
Value: Fail early, small changes, release readiness
Configuration Management (CM)
Fundamental building block of CI/CD and DevOps
Adding configuration to software repositories (git)
configuration management (cm)
How should the code be developed?
e.g. IDE configuration
configuration management (cm)
What is needed to run/test/install the software?
[project]
name = "flask_app"
version = "1.0.0"
description = "Hello World app for SEM lecture"
dependencies = [
"flask ~= 3.0",
]
[build-system]
requires = ["flit_core<4"]
build-backend = "flit_core.buildapi"
[tool.pytest.ini_options]
testpaths = ["tests"]
[tool.coverage.run]
branch = true
source = ["flask_app"]
configuration management (cm)
What is needed to deploy the software? (1/2)
import os
workers = int(os.environ.get("GUNICORN_PROCESSES", "2"))
threads = int(os.environ.get("GUNICORN_THREADS", "4"))
bind = os.environ.get("GUNICORN_BIND", "0.0.0.0:8080")
forwarded_allow_ips = "*"
secure_scheme_headers = {"X-Forwarded-Proto": "https"}
Config deployment
configuration management (cm)
What is needed to deploy the software? (2/2)
FROM python:3.11-slim
RUN mkdir /app
COPY . /app
WORKDIR /app
RUN pip3 install .
EXPOSE 8080
CMD ["gunicorn","--config", "gunicorn_config.py", "flask_app:create_app()"]
Containerfile (For docker/podman)
Configuration Management (CM)
How should the code be developed?
What is needed to run/test/install the software?
What is needed to deploy the software?
All inforamation goes into code-repository
CM on developer machine
CM on developer machine
How should the code be developed?
Introduce tools which automate conventions
Example: 'pre-commit' hook to enforce mypy checks
Example: 'pre-commit' hook for automated code-formatting
CM on developer machine: pre-commit hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v2.3.0
hooks:
- id: check-yaml
- id: end-of-file-fixer
- id: trailing-whitespace
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v1.11.2 # Use the sha / tag you want to point at
hooks:
- id: mypy
- repo: https://github.com/psf/black
rev: 24.8.0
hooks:
- id: black
- repo: https://github.com/djlint/djLint
rev: v1.35.2
hooks:
- id: djlint-reformat
- id: djlint
- id: djlint-jinja
- id: djlint-reformat-jinja
.pre-commit-config.yaml
CM on developer machine: mypy pre-commit
[mypy]
disallow_untyped_defs = True
.mypy.ini
CM on developer machine: mypy pre-commit
CM on developer machine: black pre-commit
CM on developer machine
Integrate tools into IDEs
CM on developer machine
How should the code be installed/tested?
Define dependencies and tools, provide configuration
Think: Developer uses new workstation every day
Put everything into git!
CM on developer machine
Goal: Installing and launching tests should be simple
What needs to be in CM?
IDE config
References to dependencies (incl. developer tools)
Version numbers of all dependencies
Dependency configs: e.g. Database schemas
Deployment scripts
Everything!
Or maybe not exactly everything?
Everything? What really should not be in CM
Build artifacts/report (generated during build)
Passwords and other secrets
3rd party source code (use git submodules or pip)
Maintain a '.gitignore' file!
.coverage
.direnv
*.cast
__pycache__
Where to store artifacts/reports?
CI on automation server
"works on my machine" is not good enough
CI on automation server (e.g. GitHub)
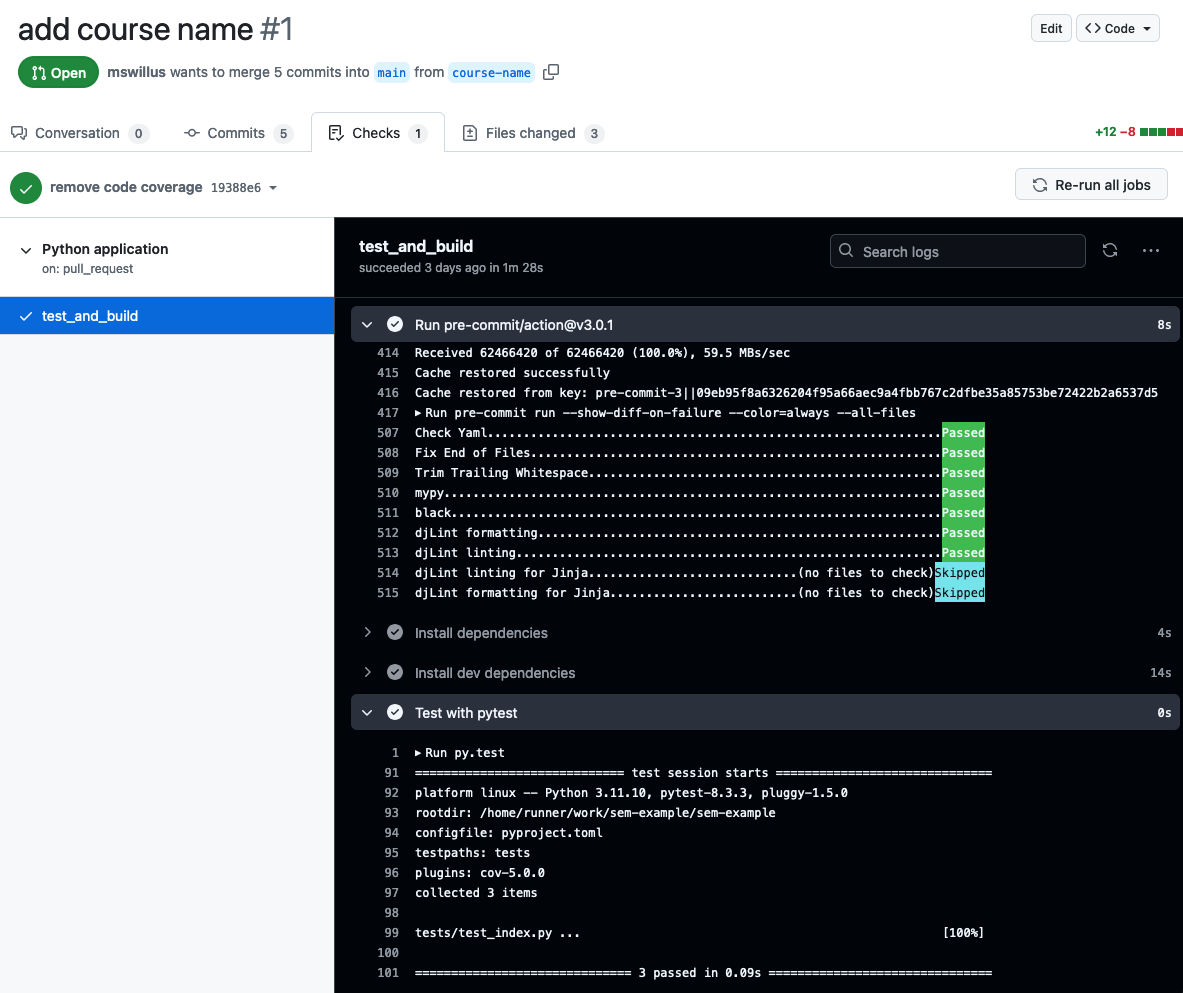
CI on automation server (e.g. GitHub)
name: Test Python application
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
test_and_build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: cachix/install-nix-action@v27
- name: Install nixpkgs
run:
nix-channel --add https://nixos.org/channels/nixpkgs-unstable && nix-channel --update
- uses: aldoborrero/direnv-nix-action@v2
with:
use_nix_profile: true
nix_channel: nixpkgs
- uses: pre-commit/action@v3.0.1
- name: Install dependencies
run:
pip install .
- name: Install dev dependencies
run:
pip install -r requirements-dev.txt
- name: Test with pytest
run:
py.test
.github/workflows/python-app.yml in repository!
CI on automation server
Run all test in well-defined environment
As close to production environment as possible
→ e.g. Use identical sources for dependencies
As close to development environment as possible
→ e.g. Run the same pre-commit hooks
Proof that all components of SW still integrate well
CI on automation server (e.g. GitHub)
Run for changes of mainline and MRs
Feedback + Easier review (Test-driven reviews)
Ideally: Reviewer does not always need to test locally
CI on automation server (e.g. GitHub)
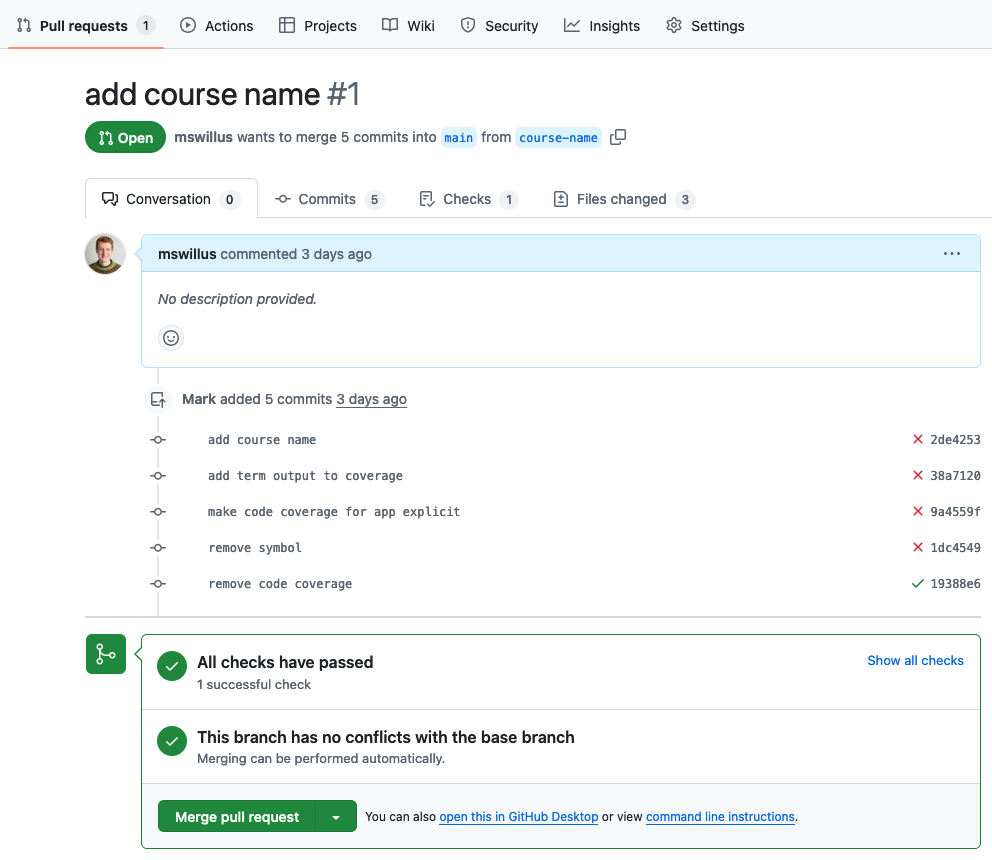
CI integrated into code review
CI on automation server (e.g. GitLab)
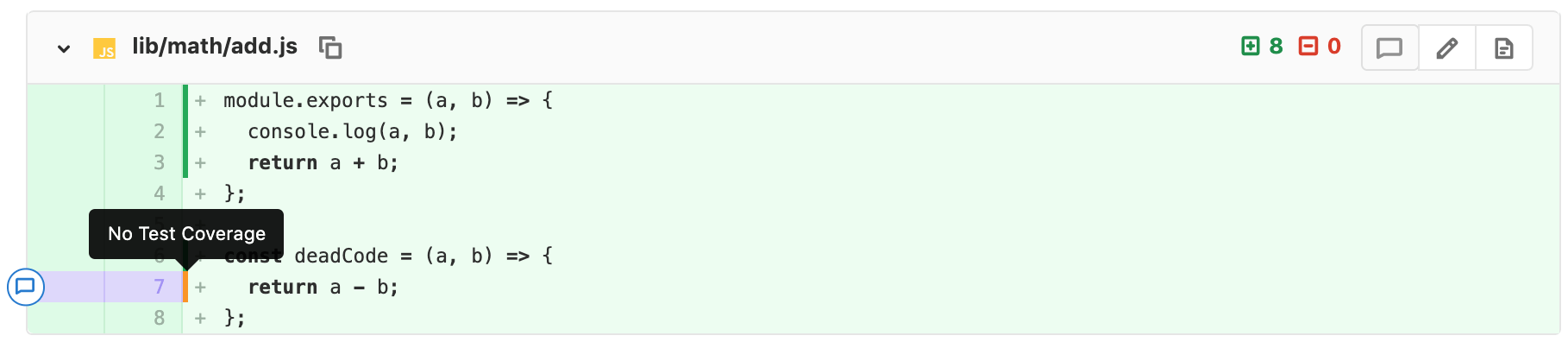
CI integrated into code review
GitLab's Test coverage visualization
CI Best practices
Commit to mainline should happen very often!
Everything needed for a release goes into git
Fixing automation issues has a (very) high priority
Pipeline errors should never be ignored
Test and build runs need to be fast
CI Benefits
Changes tend to be smaller
Consequences of changes are more transparent
Issues with system are easier to fix
Continuous delivery/deployment (CI → CD)
Continuous delivery/deployment (CI → CD)
Can deploy mainline to production at any given moment
We may choose not to
→ business decision, not technical reason
Do deploy mainline to production with every change
Examples?
Continuous delivery/deployment (CI → CD)
Can deploy vs. do deploy
Bundling features in major realeses
But always deploy security updates
Being able to always roll back to older versions
Continuous delivery/deployment (CI → CD)
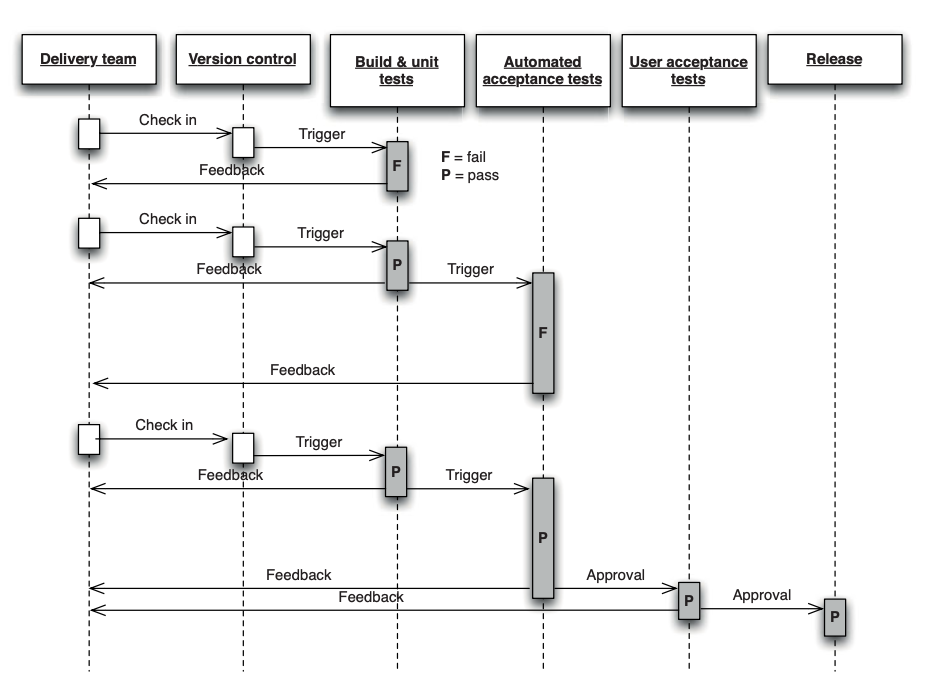
Test difficulty increases until confident
Continuous delivery/deployment (CI → CD)
Easy steps happen more often
Continuous delivery/deployment (CI → CD)
Release and deployment can be a drag
Continuous delivery/deployment (CI → CD)
"If it hurts, do it more often"
Practicing releasing (every commit) makes it easier
We learn by putting SW into production
- → Operational challanges
- → User feedback
- → Monitoring (Actual behaviour)
Continuous delivery/deployment (CI → CD)
"If it hurts, do it more often"
Iteratively create a repeatable, reliable process for releaseing software. Realeasing software should be easy!
Continuous delivery/deployment (CI → CD)
Organizational and technical challanges
CD needs to adapt to context!
Tools can only facilitate automation (No plug and play)
Tool example: python Invoke
Continuous delivery/deployment (CI → CD)
from invoke import task
@task
def clean(c, docs=False, bytecode=False, extra=''):
patterns = ['build']
if docs:
patterns.append('docs/_build')
if bytecode:
patterns.append('**/*.pyc')
if extra:
patterns.append(extra)
for pattern in patterns:
c.run("rm -rf {}".format(pattern))
@task
def build(c, docs=False):
c.run("python setup.py build")
if docs:
c.run("sphinx-build docs docs/_build")
dev@machine$ invoke clean --docs build --docs
Automate context specific tasks with invoke
CD, Development and Operations
Who is responsible in case it goes wrong?
Stability vs agility
Conflict of interest between Ops and Dev
Software Architecture Pattern: DevOps
Devops: "A cultural phenomenon"
...rather than a set of technical solutionsHow? Responsibilities and goals of
Dev and Ops are shared
Devops: "A cultural phenomenon"
"My work is more difficult and important than yours"
Instead: Encourage sharing skills
How: Mixed skills in teams
- → Add Operations folks to SW project team
- → Add Developer to Ops/Infrastructure team
- → Create DevOps teams to build bridges
Goal: Breaking down knowledge silos
Devops and code management
Using code and code management to automate tasks (incl. CI/CD)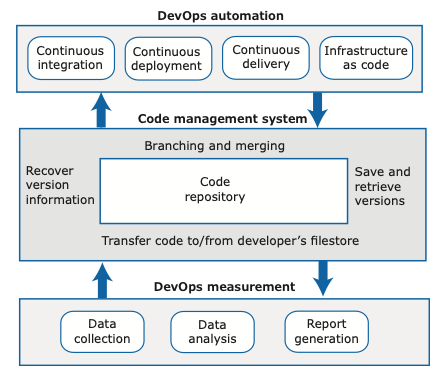
Infrastructure* as Code
*IT-Environments in organisation and the technical services that support them.
Examples?
e.g. Servers, network components, operating systems and middleware
(DNS, Load-Balancers, Routers, Firewalls, Email-servers, Telephone-Servers etc.)
Infrastructure as Code
Desired state of infrastructure is defined in configuration management (version-controlled)
Infrastructure is autonomic. It corrects itself.
Actual state of infrastructure is transparent (monitoring)
Infrastructure as Code with Terraform
terraform {
required_version = ">= 0.13"
required_providers {
libvirt = {
source = "dmacvicar/libvirt"
version = "0.6.3"
}
}
}
provider "libvirt" {
uri = "qemu+ssh://hero@192.168.165.100/system"
}
module "vm" {
source = "MonolithProjects/vm/libvirt"
version = "1.8.0"
vm_hostname_prefix = "server"
vm_count = 3
memory = "2048"
vcpu = 1
pool = "terra_pool"
system_volume = 20
share_filesystem = {
source = "/tmp"
target = "tmp"
readonly = false
}
dhcp = false
ip_address = [
"192.168.165.151",
"192.168.165.152",
"192.168.165.153"
]
ip_gateway = "192.168.165.254"
ip_nameserver = "192.168.165.104"
local_admin = "local-admin"
ssh_admin = "ci-user"
ssh_private_key = "~/.ssh/id_ed25519"
local_admin_passwd = "$6$rounds=4096$xxxxxxxxHASHEDxxxPASSWORD"
ssh_keys = [
"ssh-ed25519 AAAAxxxxxxxxxxxxSSHxxxKEY example",
]
time_zone = "CET"
os_img_url = "file:///home/myuser/ubuntu-20.04-server-cloudimg-amd64.img"
}
output "outputs" {
value = module.nodes
}
Infrastructure as Code
Infrastructure automation follows CI/CD principles
Operational systems might lack capabilities
Operations and development teams need to co-evolve
Container Orchestration
Container platforms are often used in DevOps Teams
Simple way to define virtual application environ
Virtual environment is "the same" on all platforms
Container Environment docker
FROM python:3.11-slim
RUN mkdir /app
COPY . /app
WORKDIR /app
RUN pip3 install .
EXPOSE 8080
CMD ["gunicorn","--config", "gunicorn_config.py", "flask_app:create_app()"]
Container Orchestration w/ Kubernetes
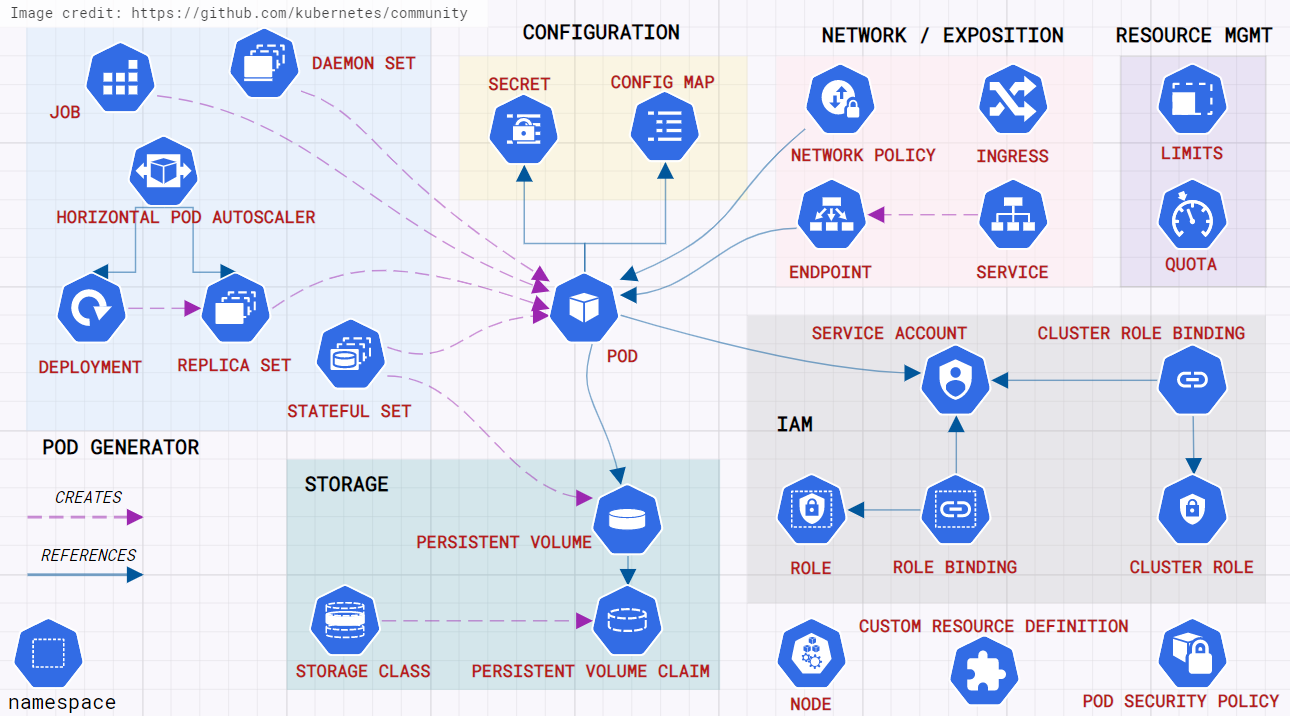
Turn whole infrastructure into virtual environment
DevOps Measurement (Monitoring)
Operations is responsible for operational status
- Identify operational metrics
- → What might indicate failure?
- → How is the application used?
- Find reliable ways to collect them
- Integrate into systems monitoring
The DevOps team now needs to provide this
devops measurement (monitoring)
Developers are now also responsible for operations!
What are Op's monitoring requirements?
Where should logs be stored?
Which monitoring tools is ops using?
Overarching goal of DevOps
Reducing blaming between dev and ops
Encourage collaboration between dev and ops
Reducing risk for operations while still embracing CD
Integrating operaions needs into software architecture
How do we get to a continuous workflows?
Start with the dev environment and make it better
Share, document and improve configs via vcs (git)
If a process is painful, do it more often
Invest time in adding and fixing automation
Concluding summary
- Software delivery is an impactful part of SE
- Releasing often has many advantages
- CI/CD pipelines to automate integration/release
- DevOps unifies goals with those of operations
- CI/CD and DevOps are adapted to orga. context